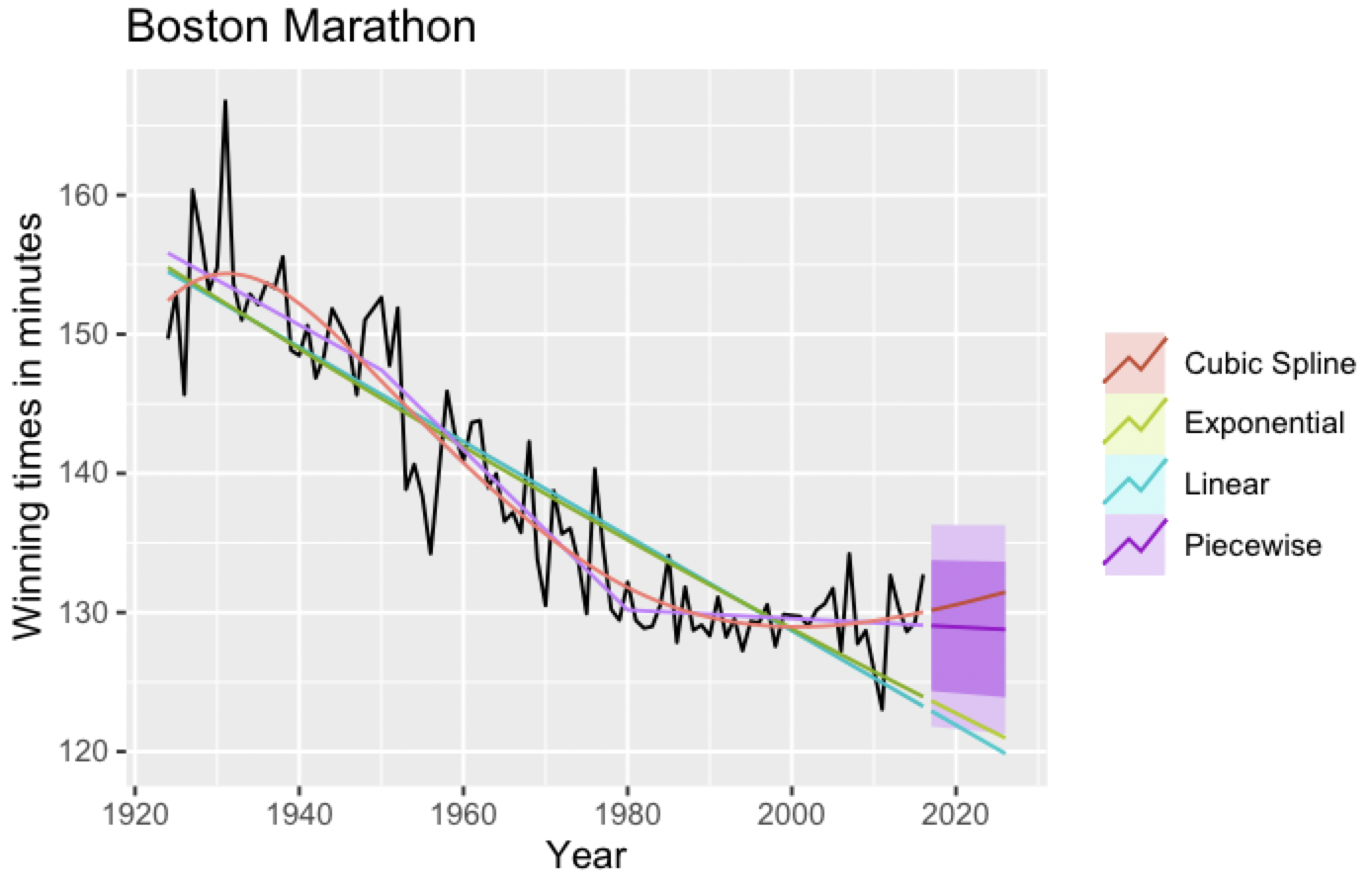
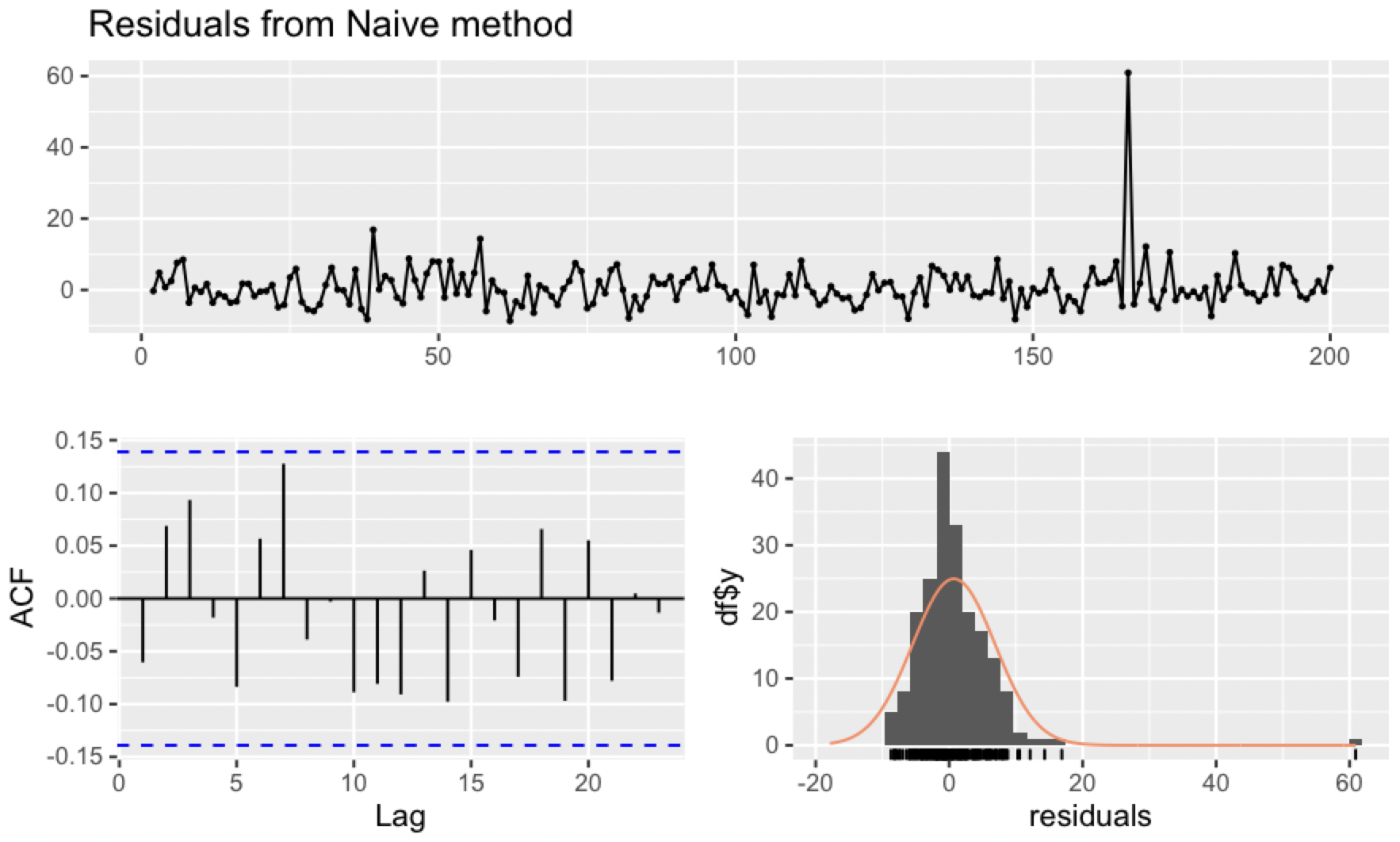
Forecasting: Principles and Practice 2nd Edition을 공부한 내용을 기록, 정리하고 있습니다. 6.6 STL 분해 STL은 Seasonl and Trend decomposition using Loess (Loess를 사용한 계절성과 추세 분해) 를 줄인 것이다. Loess regression (국소 회귀)는 데이터의 일부에 회귀를 적용하는 방식이다. 예를 들어, 과거의 데이터보다 비교적 현재에 가까운 시간에 찍힌 데이터들이 중요하다면 가까운 데이터들에 가중치를 더 부여해서 모델링을 할 수 있다. STL의 장점 (앞에서 소개한 고전분해, SEATS, X11보다 좋은) - SEAT와 X11과는 달리, 월별이나 분기별 데이터 외에도 다양한 계절성을 다룰수 있다. - 계절성이..