Forecasting: Principles and Practice 2nd Edition을 공부한 내용을 기록, 정리하고 있습니다.
3.4 예측 정확도 평가
트레이닝(학습), 테스트 데이터
모델을 선택할때, 데이터를 학습용 데이터와 테스트용 데이터로 나누는 일이 흔하다. 학습용 데이터는 모델을 만드는데 사용하고, 테스트 데이터를 사용해 해당 모델의 정확도를 측정한다. 테스트 데이터는 모델을 만드는데 사용되지 않으므로, 모델이 새로운 데이터에 어떻게 반응하는지 평가하기 좋다. 일반적으로 학습용 데이터와 테스트 데이터의 비율은 8:2로 잡는데, 어디까지 예측하고 싶은지와 샘플 사이즈에 따라 달라진다. 테스트 데이터는 최소한 예측하고자 하는 범위만큼은 커야 한다. 아래는 주의사항이다.
트레이닝 데이터에 잘 맞는다고 꼭 예측도 잘 하진 않는다.
충분한 패러미터가 있다면 데이터에 꼭 맞는 모델을 만들 수 있다.
하지만 과적합 모델은 데이터의 패턴을 파악하지 못하는 것만큼이나 좋지 못하다.
시계열 데이터를 자르는 함수
window()함수는 start/end를 이용해 데이터를 자를 수 있다.
window(ausbeer, start=1995)
subset()은 인덱스를 가지고 데이터를 선택할수 있다는 장점이 있다.
> subset(ausbeer, start=length(ausbeer)-4*5)
Qtr1 Qtr2 Qtr3 Qtr4
2005 403 408 482
2006 438 386 405 491
2007 427 383 394 473
2008 420 390 410 488
2009 415 398 419 488
2010 414 374
head(), tail() 은 데이터의 시작과 끝의 몇개 데이터를 잘라오는 식이다.
> tail(ausbeer, 4*5)
Qtr1 Qtr2 Qtr3 Qtr4
2005 408 482
2006 438 386 405 491
2007 427 383 394 473
2008 420 390 410 488
2009 415 398 419 488
2010 414 374
예측오차 (forecast errors)
예측오차는 관측값과 예측값의 차이이다. 이 오차는 관측값에서 예측할수 없었던 부분을 가리킨다. 예측오차는 잔차(residual)과 다르다.
- 잔차는 트레이닝 데이터를 가지고 계산되지만, 예측오차는 테스트 데이터를 가지고 계산된다.
- 잔차는 one-step 예측에 기반해 있다면, 예측오차는 multi-step 예측에 기반한다.
예측의 정확도는 예측오차를 사용해 측정한다.
스케일(단위)에 따른 오차 (scale dependent errors)
예측오차는 데이터와 같은 스케일(단위)을 가진다. 가장 흔하게 쓰이는 스케일에 따른 지표는 오차의 절대값이나 제곱에 기반하며 아래처럼 계산된다.

퍼센티지 오차 (percentage errors)
퍼센티지 오차는 스케일(단위)에 영향을 받지 않는다는 장점이 있으며, 따라서 다른 데이터 셋 간의 예측 성과를 비교하는데 쓰인다. 가장 흔하게 쓰이는 지표는 MAPE이다. 퍼센티지 오차의 단점은 만약 y(t)값이 0이 될 경우 값이 무한대로 가거나, y(t)가 0에 가까워지면 극단적인 값으로 변하게 된다는 점이다. 또한, 온도와 같이 측정하는 단위에 0값이 중요한 의미를 가질때도 사용하기 어렵다.
퍼센티지 오차의 마지막 단점은 양의 오차보다 음의 오차에 더 가혹한 페널티를 준다는 것이다. 이 때문에 'symmetric' MAPE (sMAPE)가 제안되었으며 아래의 공식을 따른다.
스케일 오차 (scaled errors)
스케일 오차는 다른 스케일(단위)를 가진 데이터 끼리 비교하는데 있어 퍼센티지 오차의 대안으로 제시되었다. 단순한 예측 모델의 트레이닝 MAE에 기반해 스케일 오차를 계산한다. 만약 계절성이 있는 데이터가 아니라면 단순 예측으로 아래의 공식을 사용해 스케일 오차를 계산한다.
분모와 분자 둘다 원 데이터의 스케일값을 포함하고 있기 때문에, q(j)는 데이터의 스케일에서 자유로워진다. 스케일 오차가 1보다 작다면, 트레이닝 데이터로 계산한 평균 단순예측보다 성능이 좋은 모델이라는 의미이다. 반대로, 평균 단순예측보다 성능이 나쁘면 1보다 크게 나온다.
만약 계절성 데이터인 경우라면, 스케일 오차는 계절성 단순 예측으로 정의를 내린다.
그리고 평균 절대 스케일 오차(Mean Absolute Scaled Error)는 단순히 아래처럼 표기하기도 한다.
예시
beer2 <- window(ausbeer,start=1992,end=c(2007,4))
beerfit1 <- meanf(beer2,h=10)
beerfit2 <- rwf(beer2,h=10)
beerfit3 <- snaive(beer2,h=10)
autoplot(window(ausbeer, start=1992)) +
autolayer(beerfit1, series="Mean", PI=FALSE) +
autolayer(beerfit2, series="Naïve", PI=FALSE) +
autolayer(beerfit3, series="Seasonal naïve", PI=FALSE) +
xlab("Year") + ylab("Megalitres") +
ggtitle("Forecasts for quarterly beer production") +
guides(colour=guide_legend(title="Forecast"))
이제 위 예측값들을 각기 다른 정확도 지표를 계산해서 비교해보자. 위 그래프에서 보다시피 계절성 단순 예측이 가장 관측값을 가까이 따라가고 있으며, 아래에서 계산한 정확도 지표도 계절성 단순 예측이 가장 나은 지표값을 보여주고 있다.
> accuracy(beerfit1, beer3)
ME RMSE MAE MPE MAPE MASE ACF1
Training set 0.000 43.62858 35.23438 -0.9365102 7.886776 2.463942 -0.10915105
Test set -13.775 38.44724 34.82500 -3.9698659 8.283390 2.435315 -0.06905715
Theil's U
Training set NA
Test set 0.801254
> accuracy(beerfit2, beer3)
ME RMSE MAE MPE MAPE MASE ACF1
Training set 0.4761905 65.31511 54.73016 -0.9162496 12.16415 3.827284 -0.24098292
Test set -51.4000000 62.69290 57.40000 -12.9549160 14.18442 4.013986 -0.06905715
Theil's U
Training set NA
Test set 1.254009
> accuracy(beerfit3, beer3)
ME RMSE MAE MPE MAPE MASE ACF1 Theil's U
Training set -2.133333 16.78193 14.3 -0.5537713 3.313685 1.0000000 -0.2876333 NA
Test set 5.200000 14.31084 13.4 1.1475536 3.168503 0.9370629 0.1318407 0.298728
시계열 교차 검증
좀더 세련되게 시계열 데이터를 검증하는 방법이 있다. 이 방법에서, 학습데이터는 테스트 데이터 이전에 일어난 데이터만으로 구성이 되며, 예측치를 구성할 때 미래 측정치를 전혀 사용하지 않는다. 이 방법은 작은 데이터 사이즈에는 잘 작동하지 않으므로 초기의 관측값들은 테스트 데이터로 사용하지 않는다. 아래 그림은 시계열 교차 검증법의 방법을 시각화 한 것인데, 가령 트레이닝 데이터의 다음날 데이터를 예측한다고 하면, 아래처럼 표시될 수 있다. 시간이 흐르면서 빨간 점이 오른쪽으로 한칸씩 이동하며, 정확도는 이 빨간점을 평균내어서 계산하게 된다.
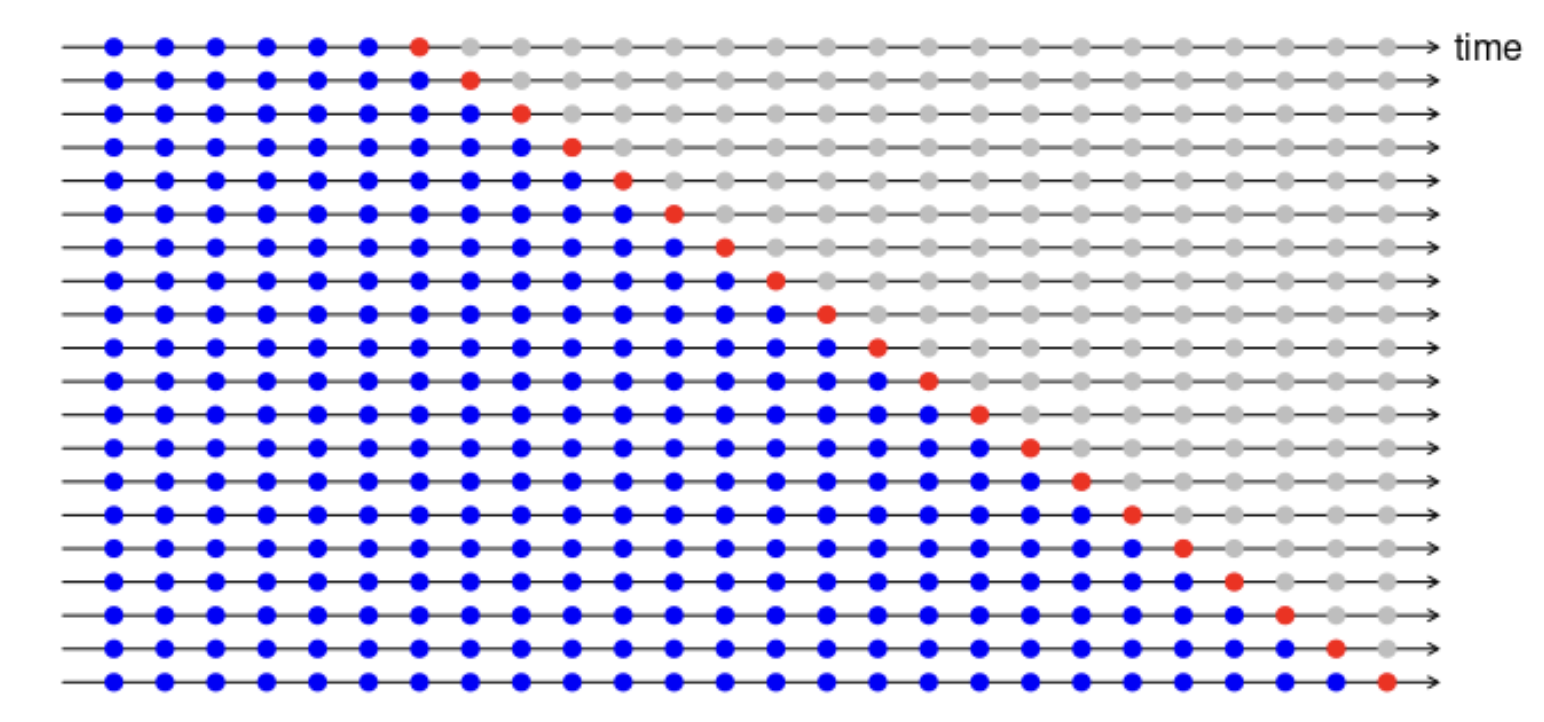
R에서 tsCV() 함수를 사용해 시계열 교차검증을 사용할 수 있다. 아래에서 시계열 교차검증(tsCV)을 통해 얻은 RMSE 지표와 잔차의 RMSE를 비교해보자. 잔차에서 나온 RMSE가 더 작은데, 이유는 예측치가 '모든' 데이터를 사용해서 나온 것이며, 진정한 예측치 (테스트 데이터)가 없었기 때문이다. 더 나은 예측모델은 tsCV방법을 사용해서 보다 작은 RMSE값을 가진 모델을 찾는 것이다.
e <- tsCV(goog200, rwf, drift=TRUE, h=1)
sqrt(mean(e^2, na.rm=TRUE))
#> [1] 6.233
sqrt(mean(residuals(rwf(goog200, drift=TRUE))^2, na.rm=TRUE))
#> [1] 6.169
'Math & Statistics > Forecasting: Principles and Practice' 카테고리의 다른 글
| 챕터 3 연습문제 (0) | 2022.02.12 |
|---|---|
| 챕터 3. 예측 구간 (prediction invervals) (0) | 2022.02.12 |
| 챕터 3 - 적합값, 잔차 (0) | 2022.02.11 |
| 챕터 3. 예측 기법 - 단순한 예측 기법 & 변환 (0) | 2022.02.08 |
| 챕터2. 연습문제 (0) | 2022.02.05 |