Forecasting: Principles and Practice 2nd Edition을 공부한 내용을 기록, 정리하고 있습니다.
3.3 잔차 진단
적합값 (fitted values)
이전의 관측값을 이용해서 예측값을 적합값(fitted values)이라고 부른다. 적합값은 항상 한 단계 예측치를 포함합니다.
잔차 (residuals)
시계열 모델에서 실제 관측값에서 모델로 맞춘 적합값을 뺀 오차값이라고 볼 수 있다. 좋은 예측 기법에서 잔차는 다음과 같은 특징을 갖는다.
1. 잔차 사이에 상관관계가 없다. 만약 있다면, 잔차에 예측값을 계산할 때 사용해야 하는 정보가 남아있는 것.
2. 잔차의 평균이 0이다. 0이 아니라면, 예측값에 편향(bias)가 있다.
필수는 아니지만 유용한 성질들:
3. 잔차의 분산이 상수이다. (constant variance)
4. 잔차가 정규분포를 따른다.
위의 3, 4번이 만족될 경우 예측구간(prediction interval)계산이 쉬워진다.
예제
주식 데이터의 경우 단순기법을 자주 사용한다. 단순기법에서 잔차를 표기하는 방법은 아래처럼 나타낼수 있다.

autoplot(goog200) +
xlab("Day") + ylab("Closing Price (US$)") +
ggtitle("Google Stock (daily ending 6 December 2013)")
위 시계열의 잔차(residuals)를 나이브 방식으로 얻어 그리면 아래처럼 된다. 166일째에 예상치 못한 주가 급등으로 큰 수의 양의 잔차가 찍혀있다.
res <- residuals(naive(goog200))
autoplot(res) + xlab("Day") + ylab("") +
ggtitle("Residuals from naïve method")
위 잔차의 분포와 평균을 히스토그램으로 확인해보자. 아래 그림을 보면 대체로 0에 가장 많이 데이터가 분포해 있고, outlier 가 하나 크게 오른쪽에 찍혀 있다 (166일에 튄 값으로 보인다).
gghistogram(res) + ggtitle("Histogram of residuals")
다음으로는 ACF를 그려본다. 여기서는 계절성과, 트렌드, 백색소음 여부를 확인할 수 있다. 잔차의 평균이 0에 가까우며, 잔차 시계열에 특별한 상관관계가 보이지 않는다. 전반적으로 잔차는 일정한 분산을 가지고 있어, 대체적으로 분산이 상수라고 볼 수 있다. 히스토그램을 볼 때 잔차는 표준분산을 따르지 않을 수도 있다 (outlier를 제외하고도 오른쪽 테일이 좀 길어보인다). 결과적으로, 분석 결과는 꽤 좋아보일 것으로 보이지만, 표준편차를 사용해서 prediction interval을 구하는 것은 조금 불확실할 수 있다.
ggAcf(res) + ggtitle("ACF of residuals")
포트만투 검정으로 자기상관관계 테스트하기
ACF를 보는 것 외에도, 자기상관관계를 확인하는 다른 방법이 있다. 포트만투 검정의 방법론은 다음과 같다. 먼저 처음 h개의 상관관계가 백색소음의 그것과 다른지 확인한다. 이런식으로 여러 상관관계 데이터를 그룹으로 묶어서 보는 것을 포트만투 검정이라고 하는데, 프랑스어로 이것저것 담는 가방이란 뜻이라고 한다.
이런 유형의 검정으로 박스-피어스 검정 (Box-Pierce Test)가 있으며, 아래 식으로 산출한다.
만약 각 r(k)가 0에 가깝다면, Q값은 작아질 것이다. 반면에 r(k) 값이 양이든 음이든 커진다면, Q값도 엄청 커질 것이다. 일반적으로 계절정이 없는 데이터에는 h=10을 쓰고, 계절성이 보이는 데이터라면 h=2m 값을 쓰는데, 여기서 m은 계절의 주기이다. h값이 너무 크다면 이 테스트가 썩 좋지 않기 때문에, 만약 h=2m이 T/5보다 크다면, h=T/5를 대신 사용하기도 한다.
비슷한 (더 정확한) 검정은 융-박스(Ljung-Box) 검정이며, 아래 식으로 산출한다.
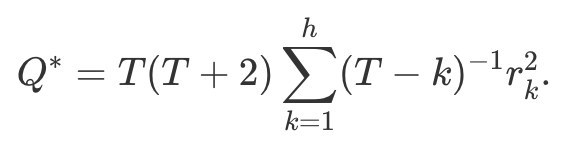
얼마나 큰 Q(*)값이 큰 것인가? 만약 자기상관관계가 백색소음에서 왔다면, Q또는 Q*값은 (h-K)의 자유도를 가진 카이제곱 분포를 가지는데, 여기서 K는 모델의 패러미터 수이다. 만약 모델의 잔차가 아니라 데이터 자체의 자기상관을 보는 중이라면, K=0이다. 위의 구글 주가 예시에서 나이브 모델은 패러미터가 없으므로, K=0으로 셋팅했다. 아래는 박스-피어스 검정과 융-박스 검정을 돌린 결과이다. 둘 다 p-value가 0.4로, 잔차가 백색소음과 차이가 없다고 결론지을 수 있다.
# lag=h and fitdf=K
Box.test(res, lag=10, fitdf=0)
#>
#> Box-Pierce test
#>
#> data: res
#> X-squared = 11, df = 10, p-value = 0.4
Box.test(res,lag=10, fitdf=0, type="Lj")
#>
#> Box-Ljung test
#>
#> data: res
#> X-squared = 11, df = 10, p-value = 0.4
이렇게 잔차를 들여다보는 함수가 R에서 편리하게 checkresiduals()함수로 있는데, 함수 하나로 여러 플롯을 한번에 다 뽑아볼 수 있으며 융-박스 테스트까지 해준다.
checkresiduals(naive(goog200))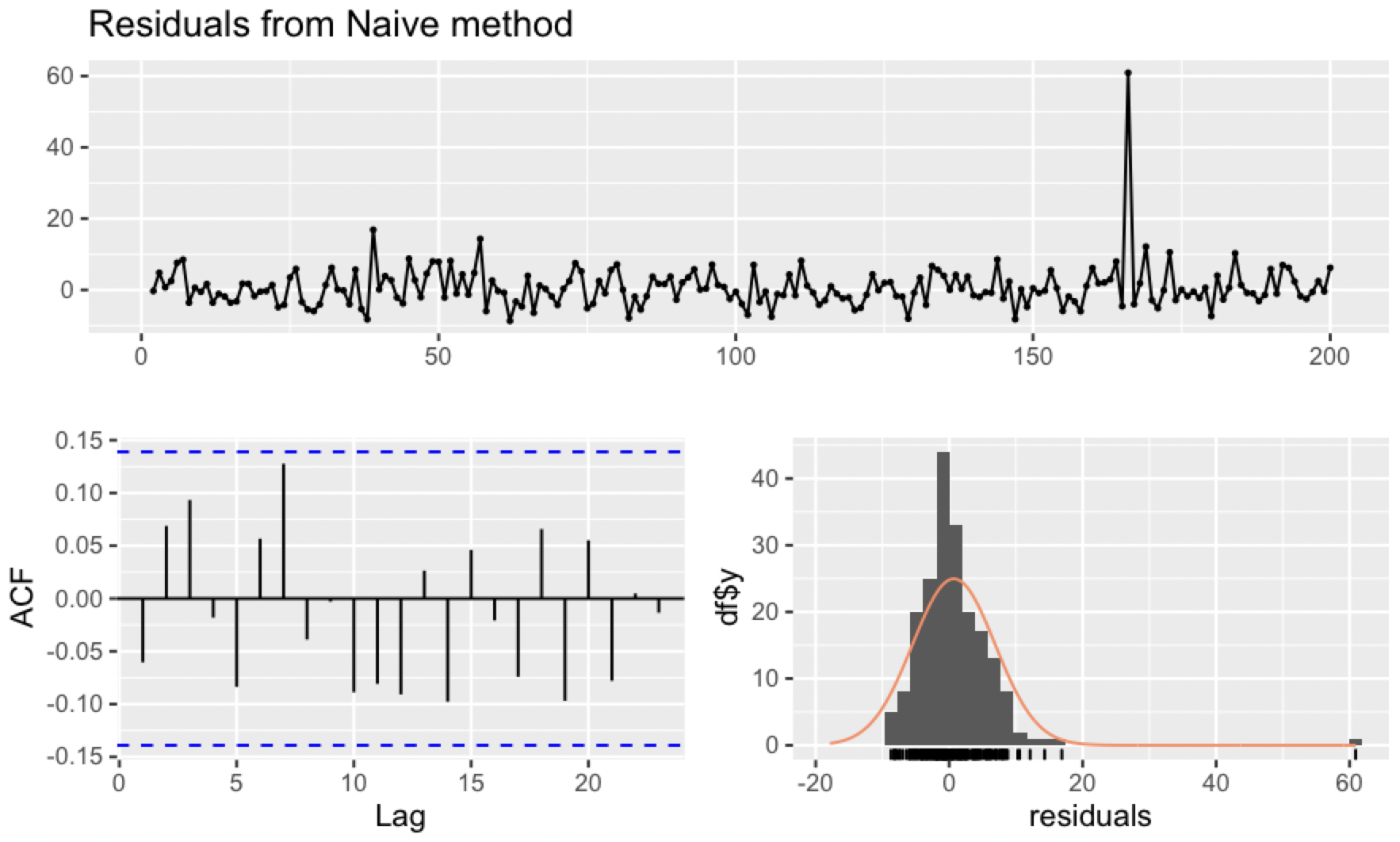
아래는 함수를 돌렸을 때 자동으로 계산되는 융-박스 검정 결과이다.
> checkresiduals(naive(goog200))
Ljung-Box test
data: Residuals from Naive method
Q* = 11.031, df = 10, p-value = 0.3551
Model df: 0. Total lags used: 10
'Math & Statistics > Forecasting: Principles and Practice' 카테고리의 다른 글
| 챕터 3. 예측 구간 (prediction invervals) (0) | 2022.02.12 |
|---|---|
| 챕터 3 - 예측 정확도 평가 (0) | 2022.02.12 |
| 챕터 3. 예측 기법 - 단순한 예측 기법 & 변환 (0) | 2022.02.08 |
| 챕터2. 연습문제 (0) | 2022.02.05 |
| 챕터2. 시계열 시각화 - 시차 그래프, ACF (0) | 2022.02.03 |